[ 데이터 모델과 SQL ]
SQLD에서 자주 나오는 파트는 크게 3개 축으로 묶인다.
- 정규화
(이상현상, 함수적 종속, 정규화 단계) - 관계와 조인
(정규화로 쪼갠 테이블을 다시 묶어 조회) - 트랜잭션
(ACID, 격리 수준 이슈) + NULL + 식별자
1. 정규화
정규화는 데이터베이스의 이상현상을 방지하기 위해,
중복을 최소화하도록 테이블을 분리하는 과정이다.
엔터티 = 테이블 = 릴레이션
시험 범위에서는 사실상 같은 개념으로 봐도 된다.
정규화를 하는 이유는
단순히 테이블을 쪼개는 게 아니라,
데이터가 바뀌거나 삭제되거나 추가될 때
생기는 문제를 원천적으로 줄이기 위해서다.
2. 이상현상 3가지
정규화를 안 하고 한 테이블에 억지로 많이 담으면,
대표적으로 3가지 이상현상이 발생한다.

1) 삽입이상
데이터를 삽입하려고 했는데,
의도하지 않은 값까지 같이 넣어야 하는 상황
예시)
학생 테이블에 휴학생(수강 정보가 없는 학생)을 넣으려면
과목, 점수 같은 칼럼 때문에 의미 없는 값(0, NULL 등)을
억지로 채워야 하는 상황이 발생
2) 삭제이상
어떤 데이터를 삭제했더니,
같이 남아 있어야 할 데이터까지
함께 사라지는 상황
예시)
특정 수강 기록을 삭제했더니
그 학생의 기본 정보까지 같이 없어지는 구조
3) 갱신이상
같은 의미의 값이 여러 곳에 중복 저장되어
일부만 수정되면 모순이 생기는 상황
예시)
같은 과목명이 여러 행에 반복 저장되어 있는데
일부 행만 수정되어 데이터 불일치 발생
3. 함수적 종속
정규화 단계의 핵심 기준은 함수적 종속이다.
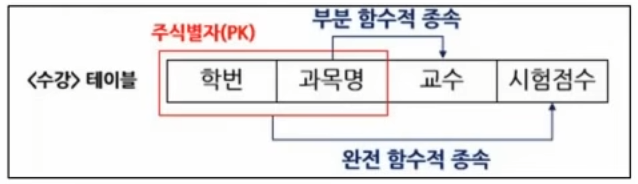
1) 함수적 종속
A 속성 값이 정해지면 B가 유일하게 결정되는 관계
표기: A → B
용어
- A: 결정자
- B: 종속자
예시)
학번 → 학생이름
학번이 같으면 학생이름은
단 한 명으로 유일하게 정해진다.
2) 완전 함수적 종속
종속자가 기본키의 모든 속성에 종속되는 경우
예시)
기본키가 (학번, 과목명)인 성적 테이블에서
시험점수는 (학번, 과목명)을 모두 알아야 유일하게 결정됨
즉 (학번, 과목명) → 시험점수
3) 부분 함수적 종속
종속자가 기본키의 일부 속성만으로 결정되는 경우
예시)
(학번, 과목명)이 기본키인데 과목명 → 담당교수 처럼,
과목명만 알아도 담당교수가 결정되는 경우
※ 부분 함수 종속이 남아 있으면 2정규화에서 걸린다.
4. 정규화 단계: 도부이결다조
정규화 단계 순서
- 제1정규화
- 제2정규화
- 제3정규화
- BCNF
- 제4정규화
- 제5정규화
※ 암기법: 도부이결다조
4.1 제1정규화: '도'메인이 원자값
한 칸(속성)에는 하나의 값만 들어가야 한다.
- 나쁜 예: A | 수학,과학
- 좋은 예: A | 수학, A | 과학
여러 값이 들어간다면
- 행을 늘리거나
- 별도 테이블로 분리한다
4.2 제2정규화: '부'분 함수 종속 제거
부분 함수 종속이 없어야 한다.
즉, 복합키를 쓸 때 기본키 전체에
완전 함수 종속이어야 한다.
- (학번, 과목명) → 시험점수 는 정상
- 과목명 → 담당교수 같은 관계가 있으면
부분 종속이므로 분리 대상
시험 감각으로 풀면 이렇게 보면 편하다.
- 주식별자 전체로만 알 수 있어야 한다
- 주식별자의 일부만으로
알 수 있는 속성이 있으면 2정규화 위반
4.3 제3정규화: '이'행 함수 종속 제거
이행 함수 종속(Transitive Dependency)을 제거한다.
형태로 보면
- A → B, B → C 이면 A → C 가 성립하는 구조
- 이때 C는 A에 직접 달린 게 아니라
B를 통해 딸려온 값이라 분리 후보가 된다.
예시)
시험점수 → 학점
학번, 과목명 → 시험점수
결국 학번, 과목명 → 학점이
되어버리는 구조는 설계 관점에서 흔들릴 수 있다.
핵심은
- 일반 속성(비키 속성)이
다른 일반 속성을 결정하면 3정규화 대상
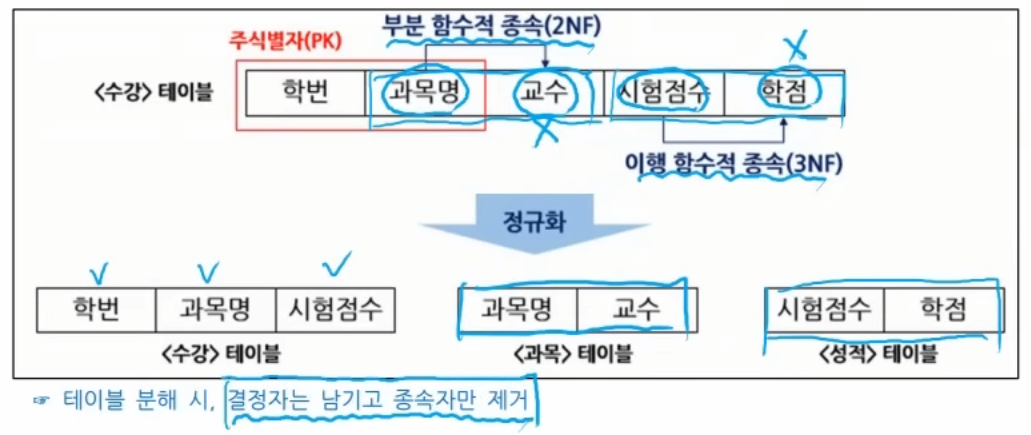
※ 2정규화/3정규화 분해 팁
테이블 분해 시 결정자는 남기고 종속자만 제거한다.
- 결정자 쪽은 부모 엔터티로 두고
- 종속자들을 별도 엔터티로 분리해 연결한다
4.4 BCNF: '결'정자가 모두 후보키
BCNF는 3정규화보다 더 엄격하다.
- 모든 결정자가 후보키(유일성을 보장하는 키)여야 한다.
- 결정자인데 후보키가 아니면 분해 대상
4.5 제4정규화: '다'치 종속 제거
다치 종속(Multi-valued Dependency)을 제거한다.
- 하나의 키에 대해 독립적인
다중 값 집합이 함께 존재할 때 발생
예시)
한 학생이 여러 취미, 여러 자격증을 갖는데
두 집합이 서로 독립이면 한 테이블에
같이 두는 순간 조합 폭발이 발생할 수 있다.
→ 분리해서 각각 관리
4.6 제5정규화: '조'인 종속성 이용
조인 종속(Join Dependency)을 기준으로
더 분해 가능한지 보는 단계
- 실무에서는 1~3정규화 + BCNF가 핵심 빈출이다
- 4, 5정규화는 개념과 키워드 중심으로
정리해두는 게 효율적이다
5. 관계와 조인의 이해
정규화를 하면 테이블이 분리된다.
따라서 관계가 있는 테이블을 SQL로 연결해 조회해야 한다.
그 연결이 바로 조인이다.
조인의 핵심 의미
- 관계(주로 PK-FK)로 연결된 테이블을
- 하나의 결과 집합처럼 조회하는 방법
주의할 점
- 정규화로 지나치게 쪼개면
조인이 많아지고 성능이 떨어질 수 있다. - 그래서 성능이나 조회 패턴 때문에
반정규화(의도적 중복)를 선택하는 경우도 있다.
간단 예시(내부 조인)
SELECT s.student_id, s.name, e.subject_id
FROM student s
JOIN enroll e
ON e.student_id = s.student_id;6. 계층형 데이터 모델
계층형 데이터는 같은 테이블 안에서
상하 관계가 있는 구조다.
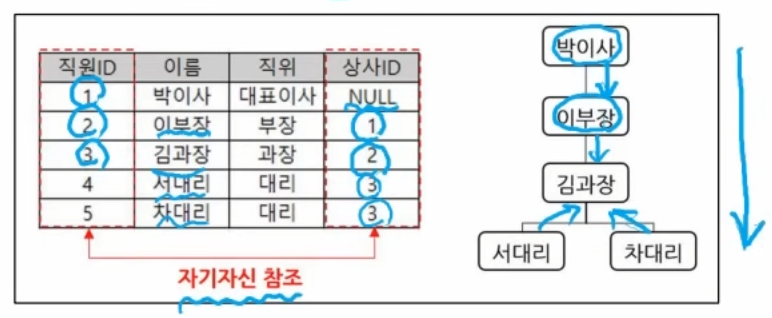
대표 예시는 '직원-상사' 구조다.
- 직원 ID
- 상사 ID(같은 직원 테이블의 직원 ID를 참조)
이런 구조는 셀프 조인(자기 자신 조인)이나
계층형 질의를 활용한다.
셀프 조인 예시
SELECT e.emp_id, e.emp_name, m.emp_name AS manager_name
FROM employee e
LEFT JOIN employee m
ON e.manager_id = m.emp_id;7. 상호배타적 관계
상호배타적 관계는 둘 중 하나만 선택되는 관계다.

예시)
주문은 개인고객 또는 법인고객 중 하나로만 들어간다.
개인고객이면서 법인고객일 수는 없다.
모델링 관점 핵심
- 하나의 관계만 성립하도록 제약을 설계해야 한다.
- 구현에서는 서브타입(개인/법인 분리) 또는
제약조건으로 강제하는 방식이 자주 등장한다.
8. 트랜잭션
트랜잭션은 데이터베이스에서 하나의 논리적 작업 단위다.
트랜잭션의 대표 연산
- 커밋: 트랜잭션이 성공적으로 끝났음을 확정하고 DB에 반영
- 롤백: 오류가 발생하면 시작 이전 상태로 되돌림
중요 포인트
트랜잭션의 요구사항은 논리적 모델링 단계에서 반영되어야 한다.
- 어떤 작업이 한 덩어리로 묶여야 하는지(원자성)
- 어떤 데이터들이 함께 바뀌어야 하는지(일관성)
- 동시성 처리 전략은 어떤지(고립성)
- 장애 시 보존 요구는 어떤지(지속성)
9. 트랜잭션의 4대 특성: ACID
[A] Atomicity 원자성
- 전부 수행되거나 전혀 수행되지 않아야 한다.
예시)
송금 중 오류가 났는데 출금만 되고
입금이 안 되는 상황은 원자성 위반
[C] Consistency 일관성
- 실행 전후로 데이터 무결성이 깨지지 않아야 한다.
예시)
송금 전후 A+B 총합이 일치해야 한다
(규칙 위반이 없어야 함)
[I] Isolation 고립성
- 동시에 실행되는 트랜잭션끼리 서로 간섭하면 안 된다.
예시)
송금 중간 상태를 다른 트랜잭션이 읽거나 수정하면 안됌
[D] Durability 지속성
- 커밋된 결과는 영구적으로 저장되어야 한다.
예시)
서버가 셧다운되어도 커밋 결과는 남아야 한다
10. 격리 수준에 따른 문제점 3가지
격리 수준(Isolation Level)이 낮으면
동시성은 좋아지지만, 다음 문제가 생길 수 있다.
1) Dirty Read
아직 커밋되지 않은 데이터를 다른 트랜잭션이 읽는 현상
2) Non-Repeatable Read
같은 쿼리를 두 번 실행했을 때 결과 값이 달라지는 현상
보통 다른 트랜잭션의 커밋으로 데이터 값이 바뀜
3) Phantom Read
같은 조건으로 두 번 조회했는데 행 개수가 달라지는 현상
보통 다른 트랜잭션의 삽입/삭제로 발생
11. NULL 속성의 이해
NULL은 '값이 없음'이 아니라
'미정의/알 수 없음'에 가까운 개념이다.
그래서 비교/연산 규칙이 다르다.
특징
- 비교 불가: NULL < 2 같은 비교는 성립하지 않는다
- 연산 불가: NULL + 1 같은 연산도 결과가 NULL이 된다
- 집계 함수에서 제외되는 경우가 많다
(예: COUNT(컬럼)은 NULL 제외)
NULL 표기(ERD 관점)
- IE 표기법: NULL 허용 여부를 명확히 확인하기 어렵다(표현이 제한적)
- Barker 표기법: NULL 허용은 o, NULL 비허용은 * 처럼 구분한다
SQL에서의 활용
- NULL 비교는 항상 IS NULL / IS NOT NULL 로 한다.
12. 본질식별자 vs 인조식별자
본질식별자
- 현실(업무)에서 자연스럽게 존재하는 식별자
- 예: 주민번호, 학번(업무에 따라), 사업자번호 등
인조식별자
- 시스템에서 인위적으로 만든 식별자
- 예: 주문번호, 수강신청번호, 게시글번호 같은 일련번호
인조식별자를 쓰는 이유
- 복합키를 계속 들고 다니면 조인이 복잡해지고 관리가 어려워진다.
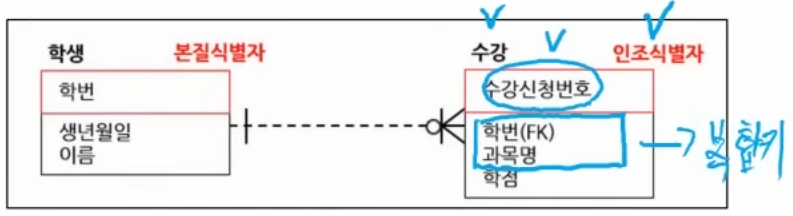
예시)
수강 테이블에서 (학번, 과목명)을 PK로 쓰면
FK도 복합으로 퍼지고다른 테이블 연결도 복잡해진다.
그래서 수강신청번호 같은 대체 PK를 두는 설계가 흔하다.
장점
- 비즈니스 변경과 분리 가능
(업무키가 바뀌어도 영향이 적음) - 개발/유지보수 용이(키가 단순, 조인 단순)
단점
- 중복 데이터 가능성
(업무적 유일성을 추가 제약으로 관리해야 할 수 있음) - 불필요한 인덱스 증가(키가 하나 더 생기므로)
마무리 요약
- 정규화 목적: 이상현상(삽입/삭제/갱신) 방지, 중복 최소화
- 함수적 종속: A → B, A는 결정자 B는 종속자
- 1정규화: 원자값(한 칸 한 값)
- 2정규화: 부분 함수 종속 제거
- 3정규화: 이행 함수 종속 제거
- BCNF: 결정자는 전부 후보키
- 조인: 정규화로 분리된 테이블을 관계로 연결해 조회
- 계층형 모델: 셀프 조인(직원-상사)
- 상호배타 관계: 둘 중 하나만 선택
- 트랜잭션: 논리적 작업 단위, 커밋/롤백
- ACID: 원자성/일관성/고립성/지속성
- 격리 문제 3종: Dirty / Non-repeatable / Phantom
- NULL: 미정의 값, 비교/연산 주의, 집계 제외 이슈
- 식별자: 본질키 vs 인조키, 인조키는 단순성과 유지보수성에 유리
'개주 훈련일지 > 🎰 SQLD 준비' 카테고리의 다른 글
| SQLD SQL 기본 (0) | 2026.02.15 |
|---|---|
| SQLD 데이터 모델링의 이해 (0) | 2026.02.08 |